Defining a calculation scheme in the XML format¶
An XML file that describes a calculation scheme can contain the following information:
- definitions of data types
- definitions of containers
- definitions of elementary calculation nodes
- definitions of composite nodes
- definitions of connections between nodes
- initialisations
These definitions will be presented progressively. We will start with:
- the definition of data types
- the definition of a sub-set of elementary nodes
- the definition of non-datastream connections
- the definition of composite nodes
We will then add complements on:
- the definition of containers
- the definition of node properties
- the definition of datastream connections
- the definition of the remaining elementary nodes.
A calculation scheme is defined using the XML proc tag. The simplest calculation scheme is as follows:
<proc>
</proc>
It contains no definition and it does nothing.
Definition of data types¶
It is impossible to define basic types other than existing types. All basic types are predefined by YACS. However, aliases can be defined. For example, an alias for the double type can be written:
<type name="mydble" kind="double"/>
we can then write mydble instead of double.
Object reference¶
The simplest way of defining an object reference type is:
<objref name="mesh"/>
The name attribute of the objref tag gives the name of the new type. The complete form to define this type would be:
<objref name="mesh" id="IDL:mesh:1.0/>
where id is the CORBA repository id of the corresponding SALOME object. This attribute has a default value that is IDL:<type name>:1.0.
All that is necessary to define an object reference type derived from another type is to add the name of the basic type(s). For example, for a derived mesh type, we can write:
<objref name="refinedmesh">
<base>mesh</base>
</objref>
If there are several basic types, we will write:
<objref name="refinedmesh">
<base>mesh</base>
<base>unautretype</base>
</objref>
As for CORBA, we can use namespaces to define types. For example, if the SALOME mesh type is defined in the myns namespace, we will write:
<objref name="myns/mesh"/>
Sequence¶
To define a double sequence, we will write:
<sequence name="myseqdble" content="double"/>
All attributes of the sequence tag are compulsory. The name attribute gives the name of the new type. The content attribute gives the name of the type of elements in the sequence. A sequence of sequences can be defined by:
<sequence name="myseqseqdble" content="myseqdble"/>
We can also define a sequence of object references by:
<sequence name="myseqmesh" content="refinedmesh"/>
Structure¶
A structure is defined using a struct tag with member sub-tags for the definition of structure members. The following is an example definition:
<struct name="S1" >
<member name="x" type="double"/>
<member name="y" type="int"/>
<member name="s" type="string"/>
<member name="b" type="bool"/>
<member name="vd" type="dblevec"/>
</struct>
The member tag has 2 compulsory attributes, firstly name that gives the member name and secondly type that gives its type. The struct tag has a compulsory “name” attribute that gives the name of the type.
Definition of elementary calculation nodes¶
Python script node¶
A Python script inline node is defined using the inline tag with the script sub-tag as in the following example:
<inline name="node1" >
<script>
<code>p1=10</code>
</script>
<outport name="p1" type="int"/>
</inline>
The name attribute (compulsory) of the inline tag is the node name. The Python script is given using the code sub-tag. As many code lines as necessary are added. A CDATA section can be used if the script contains unusual characters. This also makes it possible to assure that only one code tag is used for a complete script. For example:
<script>
<code><![CDATA[a=0
p1= 10
print "a:",a
]]>
</code>
</script>
The script calculates the variable p1 that is to be set as a node output variable. The output port “p1” of the node is defined with the outport sub-tag. This tag has two compulsory attributes: name that gives the port name, and type that gives the supported data type. This type must already be defined. To add an input data port, the import tag will be used instead of the output tag.
An example node with input and output ports:
<inline name="node1" >
<script>
<code>p1=p1+10</code>
</script>
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</inline>
The node now receives p1 as the input variable, adds 10 to it and exports it as an output variable.
If you want to execute your script node on a remote container, you have to change the tag from inline to remote and to add a tag load in the definition of the node as in the following example:
<remote name="node1" >
<script>
<code>p1=p1+10</code>
</script>
<load container="cont1" />
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</remote>
Python function node¶
A Python function node is defined using the inline tag and the function sub-tag as in the following example:
<inline name="node1" >
<function name="f">
<code>def f(p1):</code>
<code> p1=p1+10</code>
<code> return p1</code>
</function>
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</inline>
The name attribute (compulsory) of the inline tag is the node name. The only difference from the Python script node is in the execution part (function tag instead of the script tag). The function tag has a compulsory name attribute that gives the name of the function to be executed. The body of the function is given with code tags as for the script.
If you want to execute your function node on a remote container, you have to change the tag from inline to remote and to add a tag load in the definition of the node as in the following example:
<remote name="node1" >
<function name="f">
<code>def f(p1):</code>
<code> p1=p1+10</code>
<code> return p1</code>
</function>
<load container="cont1" />
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</remote>
SALOME service node¶
As stated in YACS general principles, there are two ways of describing a SALOME service node.
The first definition form uses the service tag and the component and method sub-tags as in the following example:
<service name="node4" >
<component>AddComponent</component>
<method>Add</method>
<inport name="x" type="double"/>
<inport name="y" type="double"/>
<outport name="FuncValue" type="double"/>
<outport name="z" type="double"/>
</service>
The compulsory name attribute of the service tag gives the node name. The component tag gives the name of the SALOME component to be used and method gives the name of the service to be executed. The objective in this case is to execute the AddComponent (Add component) service that is located in SALOME example components.
The second definition form uses the service tag and the node and method sub-tags as in the following example:
<service name="node5" >
<node>node4</node>
<method>Setx</method>
<inport name="x" type="double"/>
</service>
The node tag references the previously defined node4 so as to use the same component instance for node4 and node5.
Definition of connections¶
We will need to define a source node and/or a target node for all of the following concerning port connections and initialisations. In all cases, the name that will be used is the relative node name, considering the connection definition context.
Control link¶
A control link is defined using the control tag as in the following example:
<control>
<fromnode>node1</fromnode>
<tonode>node2</tonode>
</control>
The fromnode sub-tag gives the name of the node that will be executed before the node with the name given by the tonode sub-tag.
Dataflow link¶
A dataflow link is defined using the datalink tag as in the following example:
<datalink>
<fromnode>node1</fromnode> <fromport>p1</fromport>
<tonode>node2</tonode> <toport>p1</toport>
</datalink>
The fromnode and fromport sub-tags give the name of the node and the output data port that will be connected to the node and to the port for which the names are given by the tonode and toport sub-tags. The above link example states that the output variable p1 of node node1 will be sent to node node2 and used as an input variable p1.
Data link¶
A data link is defined using the same datalink tag, but adding the control attribute and setting the value equal to false. Example:
<datalink control="false">
<fromnode>node1</fromnode> <fromport>p1</fromport>
<tonode>node2</tonode> <toport>p1</toport>
</datalink>
Therefore the above dataflow link can also be written as follows:
<control>
<fromnode>node1</fromnode>
<tonode>node2</tonode>
</control>
<datalink control="false">
<fromnode>node1</fromnode> <fromport>p1</fromport>
<tonode>node2</tonode> <toport>p1</toport>
</datalink>
Initialising an input data port¶
An input data port can be initialised with constants by using the parameter tag, and the tonode, toport and value sub-tags. The toport tag gives the name of the input port of the node with the name tonode to be initialised. The initialisation constant is given by the value tag. The constant is encoded using the XML-RPC coding convention (http://www.xmlrpc.com/). Example initialisation:
<parameter>
<tonode>node1</tonode> <toport>p1</toport>
<value><string>coucou</string></value>
</parameter>
Port p1 of node node1 is initialised with a character string type constant (“coucou”).
The following gives some examples of XML-RPC coding:
| Constant | XML-RPC coding |
|---|---|
| string “coucou” | <string>coucou</string> |
| double 23. | <double>23</double> |
| integer 0 | <int>0</int> |
| boolean true | <boolean>1</boolean> |
| file | <objref>/tmp/forma01a.med</objref> |
| list of integers | <array> <data>
<value><int>1</int> </value>
<value><int>0</int> </value>
</data> </array>
|
| structure (2 members) | <struct>
<member> <name>s</name>
<value><int>1</int> </value>
</member>
<member> <name>t</name>
<value><int>1</int> </value>
</member>
</struct>
|
First example starting from previous elements¶
A complete calculation scheme can be defined with definitions of nodes, connections and initialisations.
<proc>
<inline name="node1" >
<script>
<code>p1=p1+10</code>
</script>
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</inline>
<inline name="node2" >
<script>
<code>p1=2*p1</code>
</script>
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</inline>
<service name="node4" >
<component>ECHO</component>
<method>echoDouble</method>
<inport name="p1" type="double"/>
<outport name="p1" type="double"/>
</service>
<control>
<fromnode>node1</fromnode> <tonode>node2</tonode>
</control>
<control>
<fromnode>node1</fromnode> <tonode>node4</tonode>
</control>
<datalink>
<fromnode>node1</fromnode> <fromport>p1</fromport>
<tonode>node2</tonode> <toport>p1</toport>
</datalink>
<datalink>
<fromnode>node1</fromnode> <fromport>p1</fromport>
<tonode>node4</tonode> <toport>p1</toport>
</datalink>
<parameter>
<tonode>node1</tonode> <toport>p1</toport>
<value><int>5</int></value>
</parameter>
</proc>
The scheme includes 2 Python nodes (node1, node2) and one SALOME node (node4). Nodes node2 and node4 can be executed in parallel as can be seen on the following diagram.
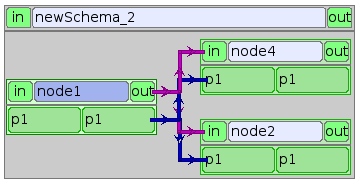
Definition of composite nodes¶
The next step is to define composite nodes, either to modularise the scheme (Block) or to introduce control structures (Loop, Switch).
Block¶
All the previous definition elements (except for data types) can be put into a Block node. A Block can be created simply by using a bloc tag with a compulsory name attribute, the name of which will be the block name. The next step is to add definitions in this tag to obtain a composite node that is a Block.
The following is an example of a Block that uses part of the above example:
<bloc name="b">
<inline name="node1" >
<script>
<code>p1=p1+10</code>
</script>
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</inline>
<service name="node4" >
<component>ECHO</component>
<method>echoDouble</method>
<inport name="p1" type="double"/>
<outport name="p1" type="double"/>
</service>
<control>
<fromnode>node1</fromnode> <tonode>node4</tonode>
</control>
<datalink>
<fromnode>node1</fromnode> <fromport>p1</fromport>
<tonode>node4</tonode> <toport>p1</toport>
</datalink>
</bloc>
This block can now be connected to other nodes like a simple elementary node. A few rules have to be respected:
- a control link crossing a block boundary cannot be created
- input and output data links crossing the boundary can be created provided that a context sensitive naming system is used (see Context sensitive naming of nodes)
ForLoop¶
A Forloop is defined using a forloop tag. This tag has a compulsory name attribute, the name of which is the node name and an optional nsteps attribute that gives the number of loop iterations to be executed. If this attribute is not specified, the node will use the value given in its input port named nsteps. The forloop tag must contain the definition of one and only one internal node that can be an elementary node or a composite node. Forloops can be nested on several levels, for example. If we would like to have more than one calculation node in the ForLoop, a Block will have to be used as the internal node.
Consider an example:
<forloop name="l1" nsteps="5">
<inline name="node2" >
<script>
<code>p1=p1+10</code>
</script>
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</inline>
</forloop>
This represents a loop that will be executed 5 times on a Python script node. The rules to be respected to create links are the same as for the blocks. To make iterative calculations, it must be possible to connect an output port of an internal node with an input port of this internal node. This is done using a data link that is defined in the context of the Forloop node.
The following example applies to looping on port p1:
<forloop name="l1" nsteps="5">
<inline name="node2" >
<script>
<code>p1=p1+10</code>
</script>
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</inline>
<datalink control="false">
<fromnode>node2</fromnode> <fromport>p1</fromport>
<tonode>node2</tonode> <toport>p1</toport>
</datalink>
</forloop>
If the number of steps in the loop is calculated, the nsteps input port of the loop will be used as in the following example:
<inline name="n" >
<script>
<code>nsteps=3</code>
</script>
<outport name="nsteps" type="int"/>
</inline>
<forloop name="l1" >
<inline name="node2" >
<script>
<code>p1=p1+10</code>
</script>
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
</inline>
</forloop>
<datalink>
<fromnode>n</fromnode><fromport>nsteps</fromport>
<tonode>l1</tonode> <toport>nsteps</toport>
</datalink>
Finally, if the internal node needs to known the current step of the loop it can use the loop output port named “index”.
WhileLoop¶
A WhileLoop is defined using the while tag. It has a single compulsory attribute “name”, that carries the node name. The input port with name “condition” must be connected for the loop to be valid.
The following is an example of a While loop that increments the variable p1 until it exceeds the value 40:
<while name="l1" >
<bloc name="b">
<inline name="node2" >
<script>
<code>p1=p1+10</code>
<code><![CDATA[condition=p1 < 40.]]> </code>
</script>
<inport name="p1" type="int"/>
<outport name="p1" type="int"/>
<outport name="condition" type="bool"/>
</inline>
<datalink control="false">
<fromnode>node2</fromnode> <fromport>p1</fromport>
<tonode>node2</tonode> <toport>p1</toport>
</datalink>
</bloc>
</while>
<datalink control="false">
<fromnode>l1.b.node2</fromnode> <fromport>condition</fromport>
<tonode>l1</tonode> <toport>condition</toport>
</datalink>
<parameter>
<tonode>l1.b.node2</tonode> <toport>p1</toport>
<value><int>23</int> </value>
</parameter>
Obviously, nested while loops can be defined.
ForEach loop¶
The ForEach loop is defined using the foreach tag. It has 2 compulsory attributes: name that bears the name of the ForEach node and type that gives the type of elements in the collection on which the loop will iterate. A third optional attribute nbranch is used to fix the number of parallel branches that the loop will manage. If this attribute is not supplied, the input data port of the loop named “nbBranches” must be connected. The foreach tag must contain the definition of one and only one internal node (elementary or composite).
The following is a minimal example of the ForEach loop:
<inline name="node0" >
<script>
<code>p1=[i*0.5 for i in range(10)]</code>
</script>
<outport name="p1" type="dblevec"/>
</inline>
<foreach name="b1" nbranch="3" type="double" >
<inline name="node2" >
<function name="f">
<code>def f(p1):</code>
<code> p1= p1+10.</code>
<code> print p1</code>
<code> return p1</code>
</function>
<inport name="p1" type="double"/>
<outport name="p1" type="double"/>
</inline>
</foreach>
<inline name="node1" >
<script>
<code>print p1</code>
</script>
<inport name="p1" type="dblevec"/>
</inline>
<datalink>
<fromnode>node0</fromnode><fromport>p1</fromport>
<tonode>b1</tonode> <toport>SmplsCollection</toport>
</datalink>
<datalink>
<fromnode>b1</fromnode><fromport>evalSamples</fromport>
<tonode>b1.node2</tonode> <toport>p1</toport>
</datalink>
<datalink>
<fromnode>b1.node2</fromnode><fromport>p1</fromport>
<tonode>node1</tonode> <toport>p1</toport>
</datalink>
A first Python script node constructs a list of doubles. This list will be used by the ForEach loop to iterate (connection to the SmplsCollection input port). The internal node of the loop is a Python function node that adds 10 to the element that it processes. Finally, the results are collected and received by the Python node node1 in the form of a list of doubles.
Switch¶
A Switch node is defined with the switch tag. It has a single compulsory name attribute that carries the name of the node. Each case is defined with the case sub-tag. The default case is defined with the default sub-tag. The case tag has a compulsory id attribute that must be an integer. The default tag has no attribute.
A minimal switch example:
<inline name="n" >
<script>
<code>select=3</code>
</script>
<outport name="select" type="int"/>
</inline>
<switch name="b1">
<case id="3">
<inline name="n2" >
<script><code>print p1</code></script>
<inport name="p1" type="double"/>
<outport name="p1" type="double"/>
</inline>
</case>
<default>
<inline name="n2" >
<script><code>print p1</code></script>
<inport name="p1" type="double"/>
<outport name="p1" type="double"/>
</inline>
</default>
</switch>
<control> <fromnode>n</fromnode> <tonode>b1</tonode> </control>
<datalink> <fromnode>n</fromnode><fromport>select</fromport>
<tonode>b1</tonode> <toport>select</toport> </datalink>
<parameter>
<tonode>b1.p3_n2</tonode> <toport>p1</toport>
<value><double>54</double> </value>
</parameter>
<parameter>
<tonode>b1.default_n2</tonode> <toport>p1</toport>
<value><double>54</double> </value>
</parameter>
OptimizerLoop¶
An OptimizerLoop node is defined with the optimizer tag. It has a compulsory name attribute that carries the name of the node. It has two other compulsory attributes (lib and entry) that define the C++ or Python plugin (parameters with same names). It can have the attribute nbranch or an input port nbBranches to define the number of branches of the loop. The OptimizerLoop ports (nbBranches, algoInit, evalSamples, evalResults and algoResults) need not be defined as they are already defined at the creation of the node.
A minimal OptimizerLoop example:
<optimizer name="b1" nbranch="1" lib="myalgo2.py" entry="async" >
<inline name="node2" >
<script>
<code><![CDATA[print "input node:",p1
p1=5
]]></code>
</script>
<inport name="p1" type="double"/>
<outport name="p1" type="int"/>
</inline>
</optimizer>
<datalink>
<fromnode>b1</fromnode><fromport>evalSamples</fromport>
<tonode>b1.node2</tonode> <toport>p1</toport>
</datalink>
<datalink control="false" >
<fromnode>b1.node2</fromnode><fromport>p1</fromport>
<tonode>b1</tonode> <toport>evalResults</toport>
</datalink>
Definition of containers¶
YACS containers must be defined immediately after data types have been defined and before calculation nodes are defined. A container is defined using the container tag. This tag has a single compulsory attribute that is the container name. Constraints on placement of the container are specified using properties defined with the property sub-tag. This tag has two compulsory attributes, the name and the value, that give the name of the constraint and its value in the form of a character string.
The following is an example of a container defined by the graphic user interface:
<container name="DefaultContainer">
<property name="container_name" value="FactoryServer"/>
<property name="cpu_clock" value="0"/>
<property name="hostname" value="localhost"/>
<property name="isMPI" value="false"/>
<property name="mem_mb" value="0"/>
<property name="nb_component_nodes" value="0"/>
<property name="nb_node" value="0"/>
<property name="nb_proc_per_node" value="0"/>
<property name="parallelLib" value=""/>
<property name="workingdir" value=""/>
</container>
Once containers have been defined, SALOME components can be placed on this container. This information simply has to be added into the definition of the SALOME service node using the load sub-tag. This tag has a single compulsory attribute named container that gives the name of the container on which the SALOME component will be located.
If the SALOME service defined above is to be placed on the DefaultContainer container, we will write:
<service name="node4" >
<component>AddComponent</component>
<load container="DefaultContainer"/>
<method>Add</method>
<inport name="x" type="double"/>
<inport name="y" type="double"/>
<outport name="FuncValue" type="double"/>
<outport name="z" type="double"/>
</service>
Node properties¶
Properties can be defined for all elementary and composite nodes. However, they will only really be useful for SALOME service nodes.
A property is defined by adding a property sub-tag in the definition of a node. The property tag has 2 compulsory attributes, name and value, that carry the name of the property and its value in the form of a character string.
Example with a SALOME service node:
<service name="node4" >
<component>AddComponent</component>
<method>Add</method>
<property name="VERBOSE" value="2" />
<inport name="x" type="double"/>
<inport name="y" type="double"/>
<outport name="FuncValue" type="double"/>
<outport name="z" type="double"/>
</service>
In the case of a SALOME service node, the property is transmitted to the component and by default is set as an environment variable.
Active study¶
To execute a schema in the context of a SALOME study, you have to set the DefaultStudyID property of the schema.
Example to execute the schema in the study with studyId 5:
<proc name="myschema">
<property name="DefaultStudyID" value="5"/>
...
</proc>
Datastream connections¶
Datastream connections are only possible for SALOME service nodes, as we have seen in YACS general principles. Firstly, datastream ports have to be defined in the service node. An input datastream port is defined with the instream subtag. This tag has 2 compulsory attributes, firstly name that gives the port name and secondly type that gives the supported data type (see YACS general principles for datastream types). The outstream tag is used instead of the instream tag to define an output datastream port. The property sub-tag is used with its two attributes name and value to define a property associated with the port. See Guide for the use of CALCIUM coupling in SALOME for a list of possible properties.
The following gives an example definition of the SALOME service node with datastream ports. It is the DSCCODC component that can be found in the DSCCODES module in the EXAMPLES base. Datastream ports are of the integer type with time dependence.
<service name="node1" >
<component>DSCCODC</component>
<method>prun</method>
<inport name="niter" type="int"/>
<instream name="ETP_EN" type="CALCIUM_integer">
<property name="DependencyType" value="TIME_DEPENDENCY"/>
</instream>
<outstream name="STP_EN" type="CALCIUM_integer">
<property name="DependencyType" value="TIME_DEPENDENCY"/>
</outstream>
</service>
The stream tag is used to define datastream links. Fromnode and fromport sub-tags give the name of the node and the output datastream port that will be connected to the node and to the port, the names of which are given by the tonode and toport sub-tags. The parameters for a datastream link can be set with properties (see Guide for the use of CALCIUM coupling in SALOME). A property is defined with the property sub-tag.
The following is a more complete example with parameters set for datastream links. There are two SALOME components with integer type datastream ports with time dependency (TIME_DEPENDENCY). The datastream connections use an explicit time scheme (TI_SCHEM).
<service name="node1" >
<component>DSCCODC</component>
<method>prun</method>
<inport name="niter" type="int"/>
<instream name="ETP_EN" type="CALCIUM_integer">
<property name="DependencyType" value="TIME_DEPENDENCY"/>
</instream>
<outstream name="STP_EN" type="CALCIUM_integer">
<property name="DependencyType" value="TIME_DEPENDENCY"/>
</outstream>
</service>
<service name="node2" >
<component>DSCCODD</component>
<method>prun</method>
<inport name="niter" type="int"/>
<instream name="ETP_EN" type="CALCIUM_integer">
<property name="DependencyType" value="TIME_DEPENDENCY"/>
</instream>
<outstream name="STP_EN" type="CALCIUM_integer">
<property name="DependencyType" value="TIME_DEPENDENCY"/>
</outstream>
</service>
<stream>
<fromnode>node2</fromnode> <fromport>STP_EN</fromport>
<tonode>node1</tonode> <toport>ETP_EN</toport>
<property name="DateCalSchem" value="TI_SCHEM"/>
</stream>
<stream>
<fromnode>node1</fromnode> <fromport>STP_EN</fromport>
<tonode>node2</tonode> <toport>ETP_EN</toport>
<property name="DateCalSchem" value="TI_SCHEM"/>
</stream>
Other elementary nodes¶
SalomePython node¶
This type of node is defined with the sinline tag. It has a compulsory attribute name that carries the node name. It is defined using the same sub-tags as for the Python function node: function for the Python code to be executed, inport and outport to define its input and output data ports. The placement on a container is defined using the load sub-tag as for the SALOME service node.
The following is an example of a call to the PYHELLO component from a SalomePython node:
<sinline name="node1" >
<function name="f">
<code>import salome</code>
<code>salome.salome_init()</code>
<code>import PYHELLO_ORB</code>
<code>def f(p1):</code>
<code> print __container__from__YACS__</code>
<code> machine,container=__container__from__YACS__.split('/')</code>
<code> param={}</code>
<code> param['hostname']=machine</code>
<code> param['container_name']=container</code>
<code> compo=salome.lcc.LoadComponent(param, "PYHELLO")</code>
<code> print compo.makeBanner(p1)</code>
<code> print p1</code>
</function>
<load container="A"/>
<inport name="p1" type="string"/>
</sinline>
The PYHELLO component will be placed on container A. YACS selects the container. The result of the choice is accessible in the python __container_from_YACS__ variable and is used by the node to load the component using the SALOME LifeCycle.
Datain node¶
This type of node is defined with the datanode tag. It has a compulsory attribute name that carries the node name. Node data are defined using the parameter sub-tag. This tag has two compulsory attributes, name and type, that give the data name and its type respectively. The initial value of the data is supplied by the value sub-tag of the parameter tag using the XML-RPC coding (see Initialising an input data port).
The following is an example of a DataIn node that defines two double type data (b and c) and a file type data (f):
<datanode name="a">
<parameter name="f" type="file">
<value><objref>f.data</objref></value>
</parameter>
<parameter name="b" type="double" ><value><double>5.</double></value></parameter>
<parameter name="c" type="double" ><value><double>-1.</double></value></parameter>
</datanode>
DataOut node¶
This type of node is defined with the outnode tag. It has a compulsory attribute, name and an optional attribute, ref. The name attribute carries the node name. The ref attribute gives the file name in which the values of results will be saved. The parameter sub-tag is used to define results of the node. This tag has two compulsory attributes, name and type, that give the result name and its type respectively, and one optional attribute, ref. The ref attribute is only useful for file results. If it is defined, the result file will be copied into the file with the name given by the attribute. Otherwise, the file will be a temporary file usually located in the /tmp directory (possibly on a remote machine).
The following is an example of a DataOut node that defines 5 results (a, b, c, d, f) of different types (double, int, string, doubles vector, file) and writes the corresponding values in the g.data file. The result file will be copied into the local file myfile:
<outnode name="out" ref="g.data">
<parameter name="a" type="double" />
<parameter name="b" type="int" />
<parameter name="c" type="string" />
<parameter name="d" type="dblevec" />
<parameter name="f" type="file" ref="myfile"/>
</outnode>
StudyIn node¶
This type of node is defined as a DataIn node with the datanode tag. All that is necessary is to add the kind attribute with the “study” value. The associated study is given by a property (property tag) named StudyID (the value of which is an integer).
The parameter sub-tag will be used to define the node data. This tag has two compulsory attributes, name and type, that give the data name and type respectively. The ref attribute gives the input into the study in the form of a SALOME Entry, or a path in the study tree structure.
The following is an example of a StudyIn node that defines 2 data (b and c) with types GEOM_Object and Boolean. It is assumed that SALOME has loaded the study (with StudyID 1) into memory. Data b is referenced by a SALOME Entry. The data c is referenced by a path in the study tree structure.
<datanode name="s" kind="study" >
<property name="StudyID" value="1" />
<parameter name="b" type="GEOM/GEOM_Object" ref="0:1:2:2"/>
<parameter name="c" type="bool" ref="/Geometry/Box_1"/>
</datanode>
StudyOut node¶
This type of node is defined as a DataOut node with the outnode tag and the name attribute. All that is necessary is to add the kind attribute with the value “study”. The optional ref attribute gives the name of the file in which the study will be saved at the end of the calculation. The associated study is given by a property (property tag) with name StudyID (the value of which is an integer).
The parameter sub-tag will be used to define the node results. This tag has two compulsory attributes, name and type, that give the data name and type respectively. The ref attribute gives the entry into the study in the form of a SALOME Entry, or a path in the study tree structure.
The following gives an example of the StudyOut node that defines 2 results (a and b) of the GEOM_Object type. The study used has the studyId 1. The complete study is saved in the study1.hdf file at the end of the calculation:
<outnode name="o" kind="study" ref="stud1.hdf">
<property name="StudyID" value="1"/>
<parameter name="a" type="GEOM/GEOM_Object" ref="/Geometry/YacsFuse"/>
<parameter name="b" type="GEOM/GEOM_Object" ref="0:1:1:6"/>
</outnode>