Version: 8.3.0
One of the most basic concept mainly used all over MEDCoupling is the MEDCoupling array.
This concept is used all over the MEDCoupling, ParaMEDMEM, and MEDLoader modules so it should be correctly understood to efficiently deal with Meshes and Fields.
DataArrays are the atomic element of potentially heavy-memory objects in the 3 modules mentionned above.
There are for the moment two types of arrays :
DataArrayDouble and DataArrayInt classes inherits from DataArray non instantiable class that factorizes some common methods of inherited instantiable classes.
In the rest of the documentation DataArray will be used for both DataArrayDouble and DataArrayInt.
It will be presented in this section common concept shared by the two classes to DataArrayDouble and DataArrayInt.
A DataArray instance has an attribute name.
name is particularly useful for DataArray representing profiles, families, groups, fields in MEDLoader. But excepted these useful usecases, name attribute is often ignored when DataArrays are aggregated (field array, connectivity, coordinates) in a bigger object. Whatever the usage of the name attribute of DataArrays, all methods in MEDCoupling::DataArrayDouble and MEDCoupling::DataArrayInt class deal with name as they do for components names.
The main goal of DataArray is to store contiguous vector of atomical elements with same basic datatype (signed integers, double precision...). This vector of atomical elements is called raw data of DataArray.
The size of this vector of data is called "number of elements". So the number of bytes stored by a DataArray instance, is equal to the product of the number of elements * constant size of DataType .
As DataArray instances are designed to store vector fields, tensor fields, coordinate of nodes, the notion of components has been added.
So, DataArrays have an additional attribute that is number of components that represent the size of a contiguous set of atomical elements. The vector of atomical elements stored into DataArrays are grouped in contiguous memory set of atomical elements having each same size.
The contiguous set of atomical elements is called tuple. And each tuple stored in raw data, has a length exactly equal to the number of components of DataArray storing it.
Thus :
![\[ N_{elements}=N_{tuples}*N_{components}. \]](form_0.png)
![\[ N_{bytes}=N_{elements}*sizeof(DataType)=N_{tuples}*N_{components}*sizeof(DataType). \]](form_1.png)
In other words, raw data of DataArrays can be seen as a dense matrix, whose number of components would be the row size and number of tuples would be the column size. In this point of view of DataArrays a tuple is represented by the corresponding row in the dense matrix.
Typically in the raw data of DataArrays number of tuples is highly bigger than number of components !
To finish, raw data is stored tuples by tuples, in another words, in full interlace mode, which is the natural storage strategy in C/C++ world.
For example, let's consider a DataArray having 3 components (called x for the first component, y for the second, and z for the third) and composed by 5 tuples.
The raw data of the DataAarray instance will be organized in memory like that : 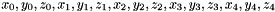 .
.
As seen in the sub section above, a DataArray instance has a defined number of components.
There is an information attached to each of these components constituting the DataArray.
This information is concretely a string of characters that allows, if needed, to give information about the corresponding component.
The format chosen in MEDCoupling for information on is "MY_COMPO_INFO [MYUNIT]". If needed, the unit attached to the component should be put between "[" and "]" after the information of the components after one space character.
DataArrays instances can consume big amount of data in memory so they inherit from TimeLabel. So in C++ it is a good practice to use :
getConstPointer method in readonly access.getPointer method only if write is needed.If the user in C++ or Python wants to modify intensively its big DataArray instance not using raw data pointer it is better to invoke setIJSilent just after invocation of declareAsNew instead of calling setIJ method that will increment time label of DataArray instance on each call.
setIJ method usage should be reduced to little modification sessions.
Here is a description of typical usages of MEDCoupling arrays.
Here is a C++ example.
Here is a Python example.
As DataArrays are the atomic entity of potentially big memory objects into MEDCoupling , DataArrays introduces concepts of copy and comparison that will be used by aggregating classes.
For more complex objects (that aggregate themselves big objects) like MEDCoupling::MEDCouplingFieldDouble the concept of copy (shallow or deep) is less straight forward because which aggregated subobjects are copied or not.
As for all potentially heavy memory consumer objects in MEDCoupling, DataArrays implement method deepCopy. This method deeply copies an instance. The life cycle of the returned object is fully independent from the instance on which the method deepCopy has been invoked.
As DataArrays are the atomic entity of potentially big memory objects into MEDCoupling, the shallow copy simply returns the same object with the reference counter incremented.
Comparison is MEDCoupling is a concept highly sensitive because big amount of tests uses this to state about the success or the fail of these tests. There are two types of comparison :
Both DataArrayDouble and DataArrayInt provide comfort methods that fill the array with some values. These methods are:
This section is only dedicated for DataArrayDouble instances.
It is possible to apply to DataArrayDouble instance a function given by a string.
There are different API for applyFunc* methods of DataArrayDouble class.
In order to reduce as much as possible dependencies, a little dynamic formula interpreter has been developed into INTERP_KERNEL. This dynamic expression evaluator can deal the following exhaustive list :
The expression evaluator is also sensitive to the following var pattern : IVec, JVec, KVec, LVec,... ,ZVec
The dynamic expression evaluator works tuple by tuple through the raw data of DataArrayDouble instance.
The principle of the dynamic expression evaluator is the following :
This method produces a newly allocated DataArrayDouble instance having exactly the same number of components and number of tuples than the instance on which the applyFunc method is applied.
This method is useful when the evaluation expression do not need to consider the components of each tuple separately.
That's why this method of applyFunc method with one parameter accepts at most only one variable.
If it is not the case an exception is thrown as seen here :
Let's take a very simple example on a DataArrayDouble instance d having 4 tuples and 2 components.
In the next example the expression contains only one variable : smth. So smth represent a tuple of size 2.
As the example shows, the output d1 has 2 components as d.
Whereas all the components of the input of d be not considered separately, it is also, possible with applyFunc method with one parameter to build an output having same number of components than input but where components in input are treated separately.
Let's build an example using DataArrayDouble instance d defined just above.
In this example using IVec and JVec it is possible to differentiate output in component #0 and output in component #1 for DataArrayDouble instance d2.
This method also returns a newly allocated DataArrayDouble instance having the same number of tuples than the DataArrayDouble instance on which applyFunc method is called, but the contrary to previous applyFunc with one parameter version here the number of components is set by the user.
The big difference with applyFunc method with one parameter seen above is that here components of tuples are treated separately.
The method that implements it is here.
Here the number of variables appearing in the expression should be equal at most to the number of component of the DataArrayDouble instance on which applyFunc method is called.
Let's consider the following DataArrayDouble having 4 tuples with 3 components called dd.
If you intend to create a new DataArrayDouble instance called dd1 having only one component that is the result of the sum of first component and the square root of the second component and the third component the invocation should be something like this :
"f+sqrt(g)+h", there are 3 variables {"g","h","f"}. As seen in link phase in expression evaluator it is needed to match a variable to the component id. The strategy of expression evaluator is the following. Sort ascendingly variables using their names and affect component id following this sorted list. It leads to :f will be attached to component #0 of dd g will be attached to component #1 of dd h will be attached to component #2 of dd Considering the previous warning, let's try to perform an application of function to compute in a DataArrayDouble instance called dd2 starting by adding component #0 and component #2 of dd.
The expression "a+c" will add component #0 to component #1 as seen in warning section !!!! It can appear silly, but this strategy has been chosen in order to support different set of variables.
applyFuncCompo and applyFuncNamedCompo methods have been developed to remedy to that feature that can be surprising.
These two methods are explained respectively here for applyFuncCompo and here for applyFuncNamedCompo.
Whatever it is possible to find a workaround using applyFunc with 2 parameters.
Here is a solution to compute dd2 :
The method that implements it is MEDCoupling::DataArrayDouble::applyFuncCompo here.
This method is very close to applyFunc method with only two parameters.
The only difference is the mapping between variables found in expression and tuple id. Rather than using rank in string sorting as applyFunc method with only two parameters uses here the component information are considered.
Let's consider DataArrayDouble instance ddd constituted with 4 tuples containing each 3 components. The components are named respectively {"Y","AA","GG"} with following different units attached on them.
To compute the sum of the first component (component #0) and the third component (component #2) simply do that :
The method that implements it is MEDCoupling::DataArrayDouble::applyFuncNamedCompo here.
This method is very close to applyFunc method with only two parameters and applyFuncCompo.
The only difference is the mapping between variables found in expression and tuple id. Rather than using rank in string sorting as in applyFunc method with only two parameters uses or the component information as in applyFuncCompo, here an explicit vector is given in input.
Let's consider DataArrayDouble instance ddd constituted with 4 tuples containing each 3 components. To add first component (component #0) and the third component (component #2) simply do that :

